
One of the most prominent phenomena of the last decade is the advent of big data. Companies needed to find new ways to process large volumes of data as efficiently as possible1. There were many different reasons behind this, such as the increase in the number of IoT devices, the wide adoption of social media platforms, the associated tracking and advertising services and a general renewed interest of companies in accumulating more data and trying to derive value from them. This led to the creation of many systems and architectural patterns that were capable of handling these increasingly large datasets in a cost-efficient way. As with many things in software, there was a lot of hype that led people to believe that these new systems were inherently superior to their predecessors in all aspects. So, I think it’s worth analysing these systems a bit more in order to understand what these systems are useful for and what are their limitations.
Most of these systems share a common architectural characteristic we can use as a framework in this analysis. They are based on what is known as a shared-nothing architecture. Interestingly enough, this is a term originally used in a 1986 paper2, but it wasn’t widely adopted past that point. If we look back at this time, the concept of a shared-nothing architecture was in contrast to shared-memory and shared-disk architectures. A shared-memory architecture is one where multiple processors share a common central memory. A shared-disk architecture is one where multiple processors each with its own private memory share a common collection of disks. A shared-nothing architecture is one where neither memory nor peripheral storage is shared among processors. The word “processor” can have many different meanings in this definition, but in the context of this discussion let’s agree that this refers to a separate phyical machine (e.g. a server).
The benefits of a shared-nothing architecture
The concept of a shared-nothing architecture is built on top of a common technique used to build distributed systems, known as partitioning. Partitioning is the process of splitting a dataset into multiple, smaller datasets in order to assign the responsibility of storing or processing those smaller datasets to different parts of a system. This can have the following benefits:
- scalability: by splitting the system into pieces that perform smaller parts of the overall work, it is easier to make the system capable of processing bigger workloads simply by adding more of those pieces. This approach of scaling a system by adding more machines is also known as horizontal scaling (or scaling out) in contrast to the approach of just getting more powerful machines, which is known as vertical scaling (or scaling up). The former is not subject to the physical limitations of a single machine and it’s typically more cost-efficient as well.
- performance: by delegating work to different parts of a system, it is easier to achieve higher and more consistent performance. Higher performance might translate to lower latency in processing individual requests or a higher throughput in terms of how many requests are completed in a specific time window. One of the main reasons for the increased performance is the reduction in resource contention and interference between requests or data items that are assigned to different parts of a system.
- fault tolerance: splitting a system into independent parts also helps with reducing the blast radius of failures. Even if one part of a system fails completely, the other parts can keep processing some work sucessfully.
We can now have a look at a few examples of systems or architectural patterns that are based on this notion of shared-nothing and see how these benefits materialise in real life.
Load balancing
Load balancing is one of the first things that need to be done for an application that requires more than one machines to handle the load. The simplest way to do this is to have a single server that acts as the load balancer and distributes requests to the application servers. However, this load balancer is still going to be a shared part of the architecture and it is going to be suboptimal in most cases, since it will be a single point of failure and contention. As a result, the load balancing layer typically consists of multiple servers that handle incoming load and distribute it to the application servers. The end clients (e.g. customer browsers) can discover and use these load balancers through the use of DNS, which is also based on a shared-nothing architecture3. This will look like the following diagram.
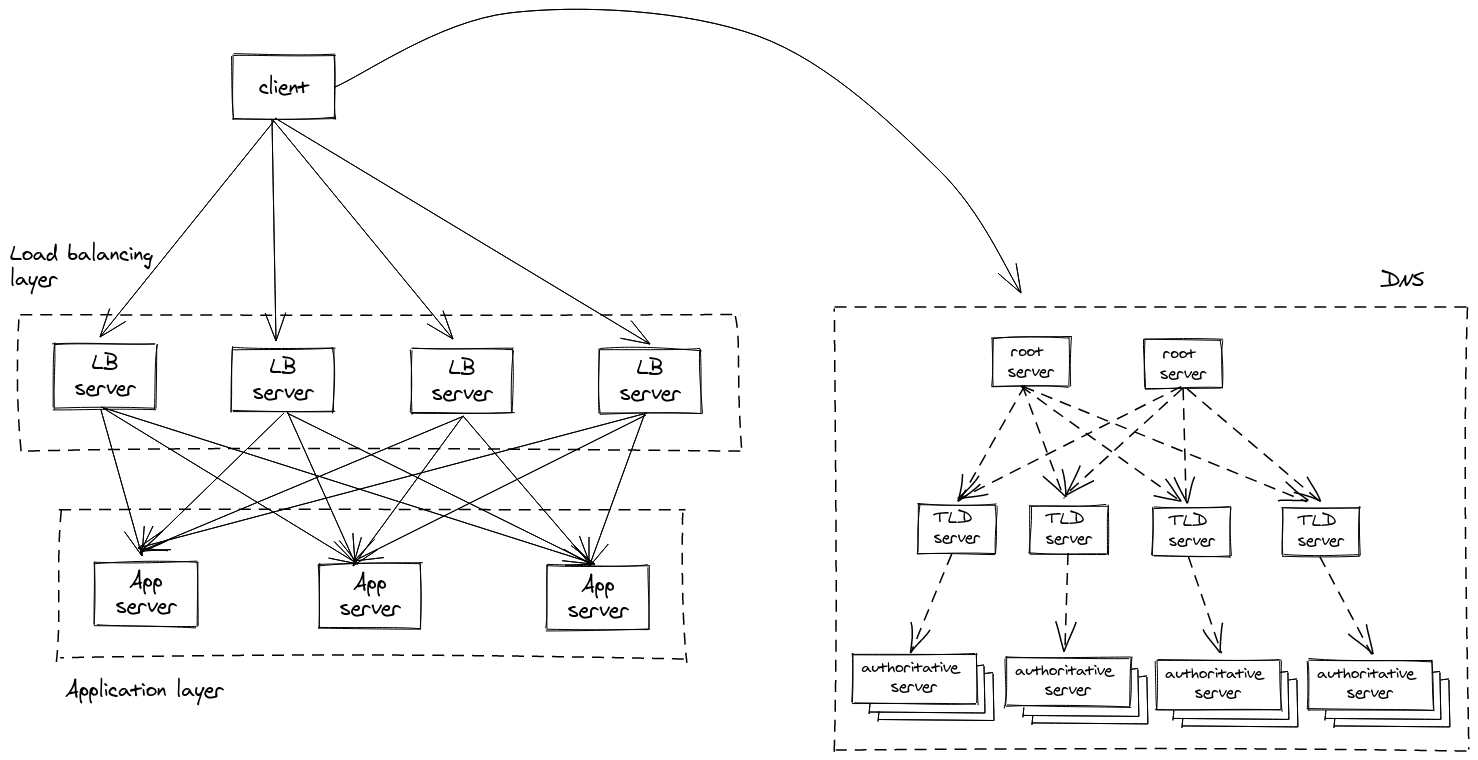
Looking back at the benefits described before, this makes it relatively easy to scale the application further, if needed. This would entail adding a new server in the fleet of the application’s servers. The way this works typically is this new application server is registered with the load balancers, which then perform occasional health checks on a specified endpoint to identify which of the registered servers are healthy and can handle incoming requests. The same process can be followed to scale the load balancer layer, if needed. One has to provision a new load balancer server and update the corresponding DNS record to include the IP address of the new machine. In the current days of cloud, the latter part can be done automatically by the cloud provider, when using services like AWS ELB or GCP Cloud Load Balancing. The redundance of multiple servers also provides the desired fault tolerance, so that if some of those servers fail traffic can be directed to the remaining ones.
Distributed data stores
The previous example assumed that the application was stateless. But, most applications need to have some form of state. A common strategy is to extract this state from the application and deploy it separately in a dedicated datastore. As an application has to store and access a larger dataset, the same need arises to scale the data layer in the same way. The same shared-nothing philosophy can be applied here and that was essentially what created all the NoSQL hype in the last decade. The idea is to split the dataset into multiple parts that are stored in different servers. Requests that want to access a data item are then routed to the proper server that has the corresponding data. Of course, this routing seems to be a central, shared functionality across the whole datastore. There are many ways to avoid having it act as a single point of failure or contention, such as employing multiple routing servers as described above, caching routing information at the client side to reduce this form of traffic or use techniques (like hash-based partitioning) that can allow the clients to perform the routing themselves. These datastores usually need to provide guarantees that a data item will be available even when any random server can fail, since a single failure is very frequent at this scale. This is typically achieved by allowing more than one servers to store every data item, so that if one of them fails requests can be handled by the remaining ones. Of course, one has to make sure these servers process requests in a controlled way, so that the dataset they are responsible for remains in a consistent form. This is done through the use of consensus protocols, where all the servers responsible for a dataset form a consensus group and require agreement from each other (e.g. a majority of the group) to perform an update to the dataset. Of course, this introduces some form of sharing between the servers in a single consensus group, but the sharing across different consensus groups is still limited. At a high-level, this looks like the following diagram.
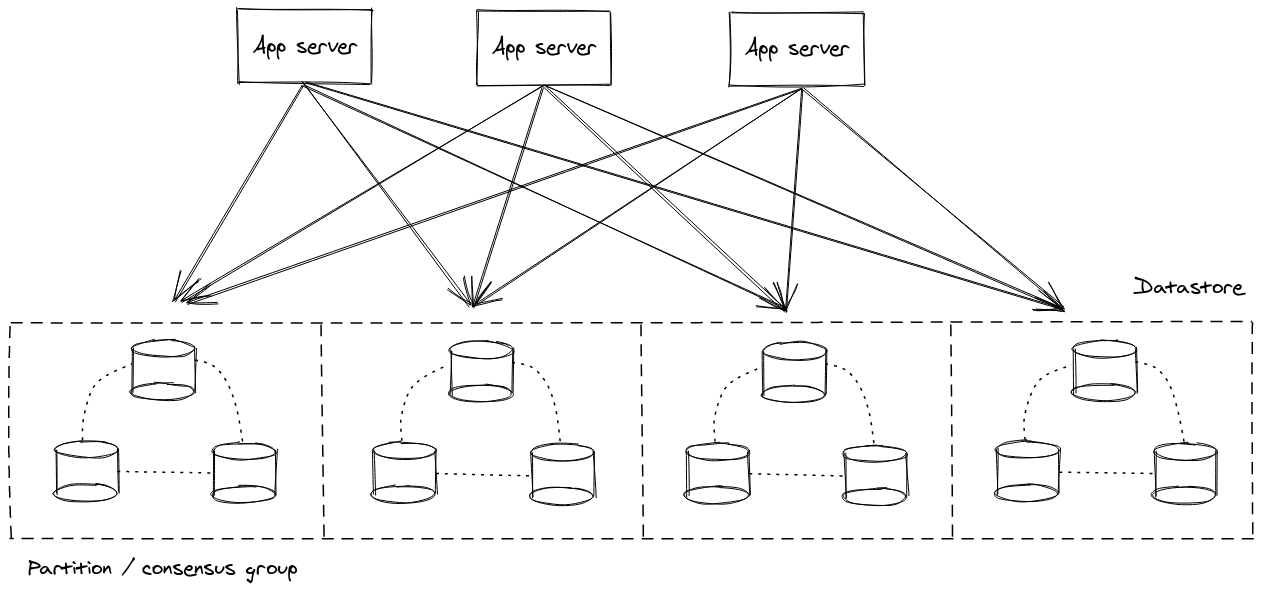
Many distributed datastores follow an architecture very close to this one nowadays, such as CockroachDB, Spanner or FaunaDB. Scaling out works by introducing a new consensus group to the cluster and assigning a piece of the dataset from other groups to this new group. The dataset owned by every group is sometimes referred to as a partition. Operations that access a single partition tend to have extremely high and consistent performance. Some datastores provide ways to access data from multiple partitions in a safe way, but this requires additional coordination and can have adverse effects on performance and availability in some cases. Other datastores elect to only allow to access data from a single partition at a time in order to provide stricter guarantees on performance and availability. At this point, I can’t help but mention that this coordination is essentially a form of sharing and it is natural to have an impact on the aspects described above. In terms of fault tolerance, this architecture ensures that every partition will be available as long as a majority of servers are functional on every consensus group.
Distributed event logs
There are some cases, where data need to be stored only temporarily, while they are being passed through differnt applications. This is usually done by using a message queue or an event log. Kafka is a distributed event log that is widely being adopted nowadays and it should be no suprise to you that it is also based on a shared-nothing architecture (otherwise it wouldn’t have been mentioned in this post!). Its architecture is very similar to that of distributed datastores, as shown in the diagram below. Data is split into partitions and each partition is stored and accessed via a group of servers that form a consensus group. The main difference is in how that data is stored physically on the servers, but that is slightly out of topic here so I won’t go into further details. Kafka also supports a form of garbage collection, called compaction, where one can allow the system to delete old data that should have been processed by the consuming application already. The scalability, performance and fault tolerance benefits play out in the same way as described for the previous examples, so I won’t repeat myself. In order to reduce coordination (and reduce the degree of sharing), Kafka provides ordering guarantees only per partition.
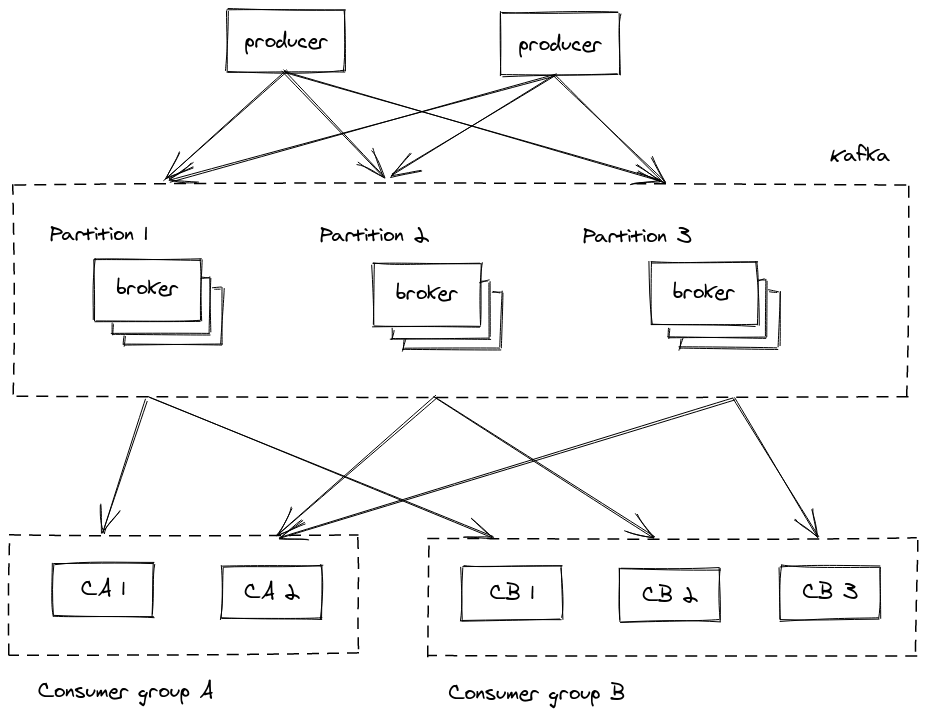
An interesting case study in the messaging space is Amazon SQS. This is not an open-source system, so there are not a lot of public details about its architecture. However, it supports two basic forms of queues, standard queues and FIFO queues. The second one provides more guarantees than the first one, such as exactly-once processing4 and first-in-first-out delivery. However, it can only support up to 300 operations per second, while a standard queue can support a nearly unlimited number of requests per second. This is a nice manifestation of the impact that increased sharing and coordination can have on performance.
Distributed data processing
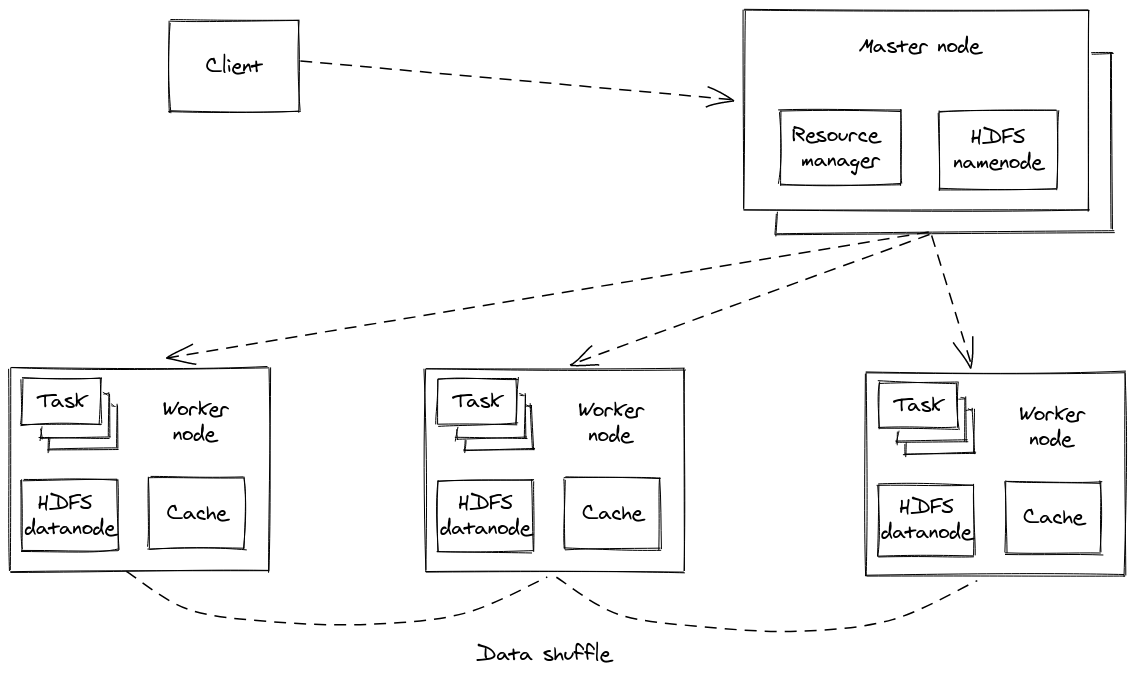
Our last example is going to be around data processing. Even if the problem of storing and accessing data is solved by using a distributed datastore, there are cases where one needs to process and analyse all of this data in aggregate, instead of accessing a small portion of it at a time. Apache Spark is an example of such a system for large-scale data processing. It operates on the same principles described above, splitting the data to be processed into smaller datasets and dividing the work into multiple workers. Nodes might fail after having completed some work and the system can recover by reassigning this work to new workers. Of course, this work might depend on input from other tasks that might have to be repeated as well. Depending on the setup5, it is also possible to identify where data reside and distribute work accordingly, so that workers are assigned work that involves data stored locally in order to utilise the network effectively and reduce traffic. This is also known as the principle of moving computation to data. This is a way to reduce sharing as much as possible, so that workers are exclusively operating on local data. However, the programming model of Spark provides many different operations that allow to process data in different ways and some of them introduce some form of sharing. For example, one might need to join data items that reside on different nodes based on a specific attribute, which means data need to be exchanged through the network between nodes. This has implications both on performance and fault tolerance. As explained previously, these join operations can cause increased network traffic that can lead to saturation of the network’s bandwidth and lower throughput. So, it is beneficial to leverage the way data is already partitioned in order to reduce the amount of data shuffle required. For example, one way to do this is to pre-partition data based on attributes that one might need to join later on. In terms of fault-tolerance, increased sharing due to join operations can lead to a cascade of many tasks that need to be repeated across many machines during a single failure, potentially over the whole dataset. On the contrary, when sharing is limited and every worker processes only a small subset of the overall dataset, then a failure of this worker will only trigger a re-execution of work that involved this specific dataset, thus limiting the blast radius of the failure significantly.
The pitfalls of a shared-nothing architecture
We have now seen the major benefits of shared-nothing architectures and some concrete examples, but one should also be aware of the pitfalls of this architecture in order to be able to make well-informed decisions. The main pitfalls are the following:
- complexity: a shared-nothing architecture comes with a lot of complexity, which is mostly a result of the increased distribution in this pattern and the big number of moving parts. If you are building a shared-nothing architecture yourself, this complexity can manifest in difficulties during implementation, software development slowdown and a bigger number of defects. If you are making use of a third-party system that is based on a shared-nothing architecture (like the ones described above), you could amortise some of these costs. However, you will still have to deal with operational complexity assuming you have to operate this system yourself. You can try and reduce the amount of operational complexity you are exposed to by resorting to some service provider that can operate this system for you, but even then there can be cases where some of this complexity can leak back to you especially during failure scenarios. So, this is one of the situations where the “keep it simple” principle can be very valuable. If you don’t have a strong need for the scalability, performance or fault-tolerance provided by a shared-nothing architecture, it’s worth considering going for a simpler architecture for the beginning and gradually migrate when time comes.
- flexibility: a shared-nothing architecture reduces coordination and sharing as much as possible in order to provide the aforementioned benefits. This means the final system ends up being more rigid and less flexible. It is easy to elaborate on what this means by leveraging the previous examples. There are many distributed datastores that follow the shared-nothing architecture and have elected to only provide key-value access to the end user. The user specifies an attribute that is used as the key and determines how items are distributed across nodes and itemss can only be queried using this attribute. This makes all the operations of such a datastore extremely efficient and fault-tolerant. However, it also makes it quite cumbersome as a tool, since the developer needs to think very carefully about the data model of an application beforehand. If a need arises to access data in a different way, this can be quite difficult to do. This can be crucial for an early-stage product that requires the ability to experiment and evolve depending on the customer feedback, but it might be unnecessary for a more mature and stable product with wider adoption that would benefit more from changes focused on making it more scalable and fault-tolerant. The same logic applies to the other examples too. For instance, a distributed datastore might abandon any consistency guarantees or multi-item transactional capabilities in order to reduce coordination, which makes application development on top of it less flexible. As mentioned already, Kafka provides ordering guarantees only inside a single partition, which can be limiting for applications that require some form of global ordering.
- cost: an extremely simplified take on the cost aspect would be “the more servers you have to run, the bigger the cost”. Even though this is useful as a rule of thumb, the reality is a bit more nuanced. From a scalability point of view, a distributed architecture usually comes with a financial overhead, which could be avoided by using a single, slightly more powerful server. However, there is a tipping point after which vertical scaling does not make sense anymore financially and you can achieve the same goal by just running multiple cheap, commodity servers. From an availability point of view, additional redundancy translates into more hardware resources and thus bigger costs. Typically, this increased availability does not translate directly into revenue, it is just a loss prevention strategy. For instance, there were claims that a single minute of downtime during PrimeDay can cost Amazon up to 1.2 million dollars. Of course, it’s perfectly valid to question how these numbers are calculated and how reliable they really are. But, the main takeway is one should try and quantify both the benefits and the costs of an architecture that provides an increased degree of availability, such as the one described here.
Of course, all of the systems described previously have their own peculiarities and subtleties, which make it somewhat pointless to try and shoehorn them into a single pattern. But, I still believe that thinking in terms of this abstract pattern and the trade-offs of reducing sharing and coordination can be very useful.
![]() Shameless plug : If you liked this blogpost, I’ve also written a book about distributed systems that you can find here.
Shameless plug : If you liked this blogpost, I’ve also written a book about distributed systems that you can find here.
-
The three commonly referenced properties of big data are volume, variety and velocity, also known as the 3Vs. ↩
-
For those interested, the paper is “The Case for Shared Nothing” by Michael Stonebraker. ↩
-
Of course, this is just one way, among the many available, to achieve this goal of load balancing. ↩
-
It’s important to note here that this guarantee of exactly-once processing only applies to the internal data stored by the queue and it’s not an end-to-end guarantee. I’ve written about this in the past here, if you are interested in reading more about it. ↩
-
The most typical deployment that allows this is deploying Spark on a Hadoop cluster, where Spark workers can reside in the same machines that also host HDFS data nodes. ↩